Machine-learning chatbot systems can be exploited to control what they say, according to boffins from Michigan State University and TAL AI Lab.
“There exists a dark side of these models – due to the vulnerability of neural networks, a neural dialogue model can be manipulated by users to say what they want, which brings in concerns about the security of practical chatbot services,” the researchers wrote in a paper (PDF) published on arXiv.
They crafted a “Reverse Dialogue Generator” (RDG) to spit out a range of inputs that match up to a particular output. Text-based models normally work the other way, where outputs are generated after having been given an input. For example, given the sentence “Hi, how are you?”, a computer learns to output a response like “Fine, thank you” as it learns that is one of the most common replies to that question in training data. The RVG, however, operates in reverse.
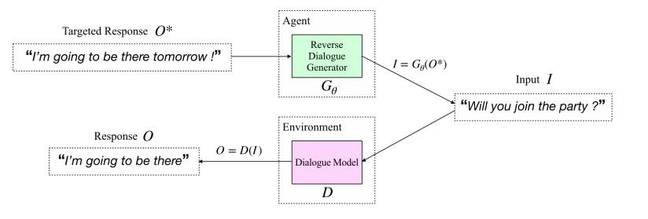
The RDG agent is tasked with generating an input to match the target output. The dialogue model is a separate chatbot the attacker is trying to probe. Image credit: Liu et al.
In this case, the agent is trying to work out what inputs would best match the output “I’m going to be there tomorrow!” since that’s what it wants to get the chatbot to say. To check how well the agent is performing, the same input “Will you join the party?” is given to a separate dialogue model – one the miscreant wants to meddle with – to see if the output is, indeed, similar to the targeted output.
If the two are similar, the agent has managed to successfully generate a good input, so that an attacker knows what to say to a chatbot to manipulate it into replying with the desired output. So here the chatbot model replies with “I’m going to be there”, which is pretty close to “I’m going to be there tomorrow!”
The example used here is pretty harmless, but imagine if the chatbot could be forced to say something racist or sexist – look at what happened to Microsoft’s trolly internet chatbot Tay. It all depends on what’s in the training data, Haochen Liu, study co-author and a PhD student at Michigan State University, told IAIDL.
“Whether we can manipulate the dialogue system to output some specific malicious responses depends on the corpus used to build the dialogue model. If the target malicious response contains a word that never appears in the training set, the word will be out of the vocabulary of the model, so it’s impossible to manipulate the model to say that.”
It’s important that the agent built by a miscreant works in a similar way to the chatbot that he or she is trying to manipulate. “By using a similar architecture for reverse dialogue generator, it’s more likely for us to find a reverse mapping of the dialogue model,” said Liu. In this project, the chatbot probed was built on Facebook’s ParlAI model, and the RDG are both based on the seq2seq model, a popular architecture used to encode and decode text in deep learning.
The agent is trained with 2.5 million human conversations on Twitter; only single tweets and their single replies are considered to create input and output pairs. Reinforcement learning is used to train the RDG; it’s awarded a good score if the input it generates is an appropriate match to a given input.
“Based on the design of our method,” Liu said, “as long as we can interact with a dialogue system for enough times, the reverse dialogue generator can learn a pattern to recover an input given an output, so the method has been designed in such a way that it is flexible to work on a dialogue model trained on any dataset, no matter whether it consists of Twitter dialogues or other dialogues.” ®
Sponsored:
Transforming infrastructure to enable top-performing development teams